
One of my current tasks at work is an auto-update feature for one of our products: check for updates, if there is one, download and install it. The downloads are pretty big, and they take a while even on a fast connection, so I decided to add one of those little time-till-completion estimators on the download window - you know, "12.3MB downloaded, 3:21 minutes left". I'd never done one of those, so I had to come up with an algorithm to do that calculation. This is the story of what I did at work today.
(warning, geeky stuff ahead)
My first approach was the simplest one I could think of; for each chunk of data downloaded, assume this ratio holds true:
-
BytesCurrent / BytesTotal = TimeCurrent / TimeTotal
And, I have three of those variables...
Or, very simply: if it's taken 30 seconds to download 30% of the data, assume it will take 100 seconds to finish 100%. And that means we have 70 seconds left. Simple. And, that works pretty well - or, at least it works like most other time estimators I've seen: at the start of a download, the time left number is far higher than expected - wildly over the mark. And that might be related to how long it takes the first chunk of data to arrive vs. when I start the timer. So, it starts bad, but eventuallly it settles down to a more realistic value, and by the tail end of the download it's pretty close - only a second or two off of expected. I'm sure you're all familiar with that phenomenon, if you've ever watched these time-left estimators in other programs. If you graph that, it looks like this:
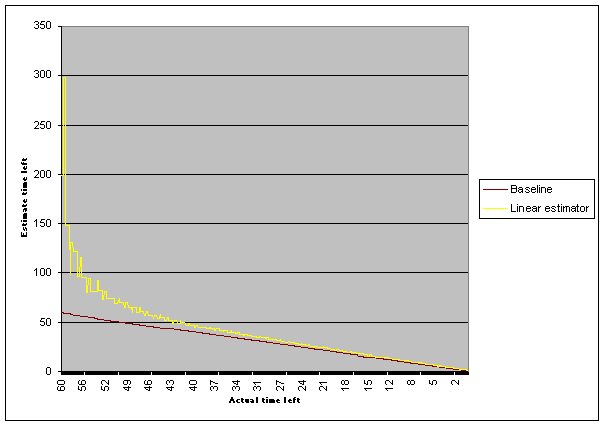
The stairstep effect is due to rounding. That red line is the expected time left - it's calculated after the fact, based on how long the download actually took. Since there's really no way to know in advance how long a download will take (due to variations in network speed, etc), no algorithm could expect to hit that. It's just for reference. But, as you can see, the simple proportional estimator is pretty good, after the download gets going for real. And that bogus startup section could probably be fixed by finding a better place to start the clock... maybe.
But, since I'm a geek, I wondered if there was a better way. I decided to try a rolling average; After each chunk of data has been downloaded:
- Store the current time and current amount downloaded in a fixed-length queue (first-in, first-out - take off the oldest data from one end of the queue, add the newest data to the other end)
- For each adjacent pair of items in the queue, caclulate a bytes per second rate:
(Bytesi - Bytesi + 1) / (Timei - Timei + 1) - Average those rates
- Divide bytes left to download by the average rate to get an estimated time left
So, here's what happens with a rolling window of ten data points:
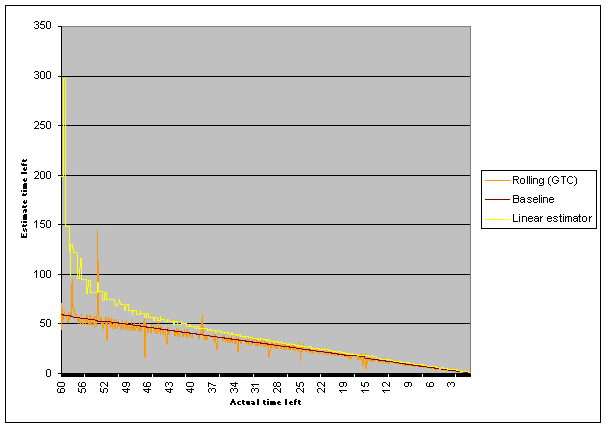
The rolling calc is the orange line.
As you can see, the rolling calc generally follows the reference line better than the simple linear proportion estimator, but it's pretty noisy - it seems to bounce around the expected value by two or three seconds. To the user that will look pretty ugly: "00:05... 00:08... 00:03... 00:05... 00:04..." Some of that noise is probably due to the fact that the timer I'm using (GetTickCount) simply isn't accurate enough to measure the time between the arrival of the data chunks. So, is there a better timer? Yes, there is; it's called QueryPerformanceCounter. Here's what happened when I use that timer:
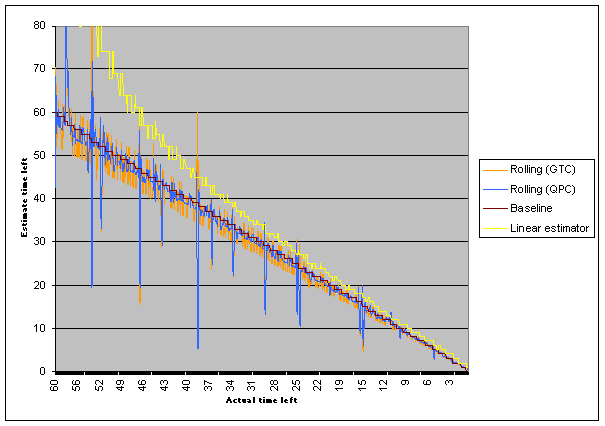
The rolling calc with QueryPerformanceTimer line is the light blue one, the rolling calc with GetTickCount is orange, the proportional estimator is yellow and thebaseline is dark red. I reduced the vertical scale on this to emphasize what's happening with the rolling calcs. As you can see, the blue line is still very noisy, but the magnitude of the noise has been reduced quite a bit. Even more interesting, though, is the fact that the spikes on the lines are pretty much identical for both rolling calcs - that means it's probably not the timer's fault, but rather it's something to do with the actual rate of the data coming in. And that makes sense, because network transfers aren't smooth; if they were, there'd be no need for an estimator like this. Still, in the well-behaved parts of the graph, using the better timer does reduce the noise in the estimates.
So, it's going pretty well. We're tracking the optimal rate pretty closely, the noise in the estimation is low, except for some pretty extreme outliers.
Is there anything else to try? What about increasing the size of the rolling window...
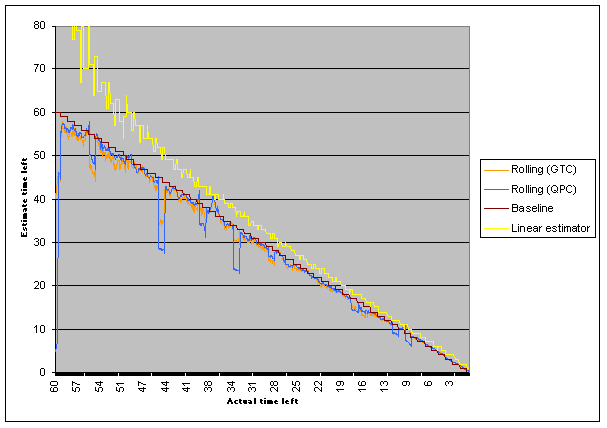
This one uses a window size of 20 points for both rolling estimators; previous graphs used a 10 point window (also, this is a different download, so the data isn't going to match with previous graphs). The spikes are shorter now, but they last longer since it takes longer for outlier data to work its way out of the queue. For a user watching the estimated time, that's probably not better. What if we reduce the window to 5 items? Well, it looks pretty much exactly like what we got for a window of 10 points. I really don't see any significant difference (so I won't bother posting the graph).
Now, time to get brutal. Those spikes have to go. Let's whip out the old statistics tools and see if we can smash those spikes into submission. Let's do a really simple outlier filter: take our list of rolling rates and knock out any points which fall more than one standard deviation from the mean. With a window of ten points, that gives us this:
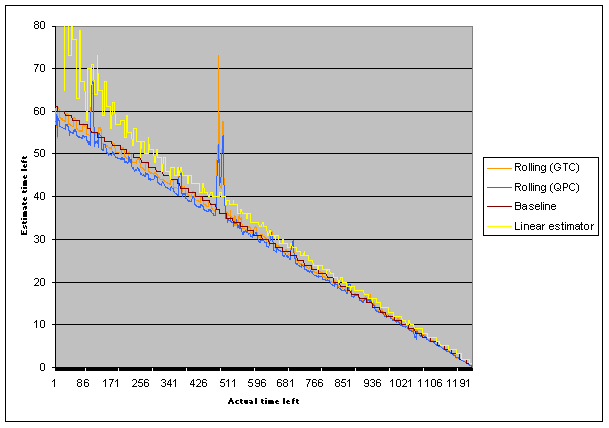
Ah ha! Spikes are receding. What if we increase the window size?
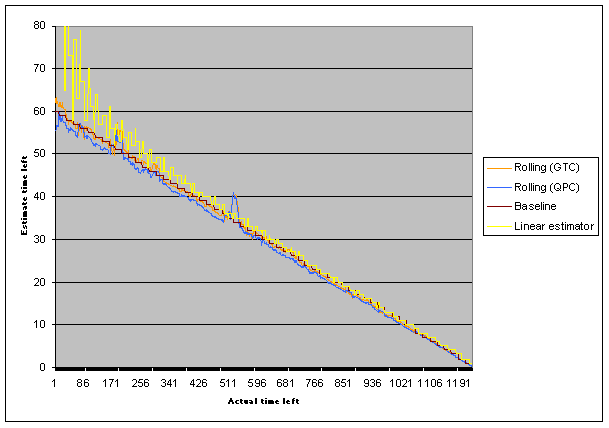
Much better. That might be as far as I can take that method.
(oops, looks like I screwed up the X-axis labels on the last two graphs. They should be the same as the other graphs)
So, the big question: Is it better than the simple method ? The first calculation assumed that everything that's happened since the start of the download predicts what will happen for the rest of the download. The rolling calculation assumes a small window into recent performance predicts future behavior. Does either model real life better ? Beats me.
After it works through the initial startup problem (which could possibly be fixed by being smart about when to start the clock), the linear method gets pretty close to both the ideal and the rolling window method. And, the simple linear method isn't very sensitive to small changes in download rate - note that bump in the middle of the rolling methods which the simple method completely ignores. And, of course, the simple method is vastly less complex than the rolling window method, which makes maintenance a lot easier, if anyone else ever has to work on it. So, maybe the simple method is better overall. And, maybe all my work was for naught - but it was fun!
Update:
All that stuff above was done on a Saturday afternoon. When I came into work Monday AM, I tried the download again. Big difference...
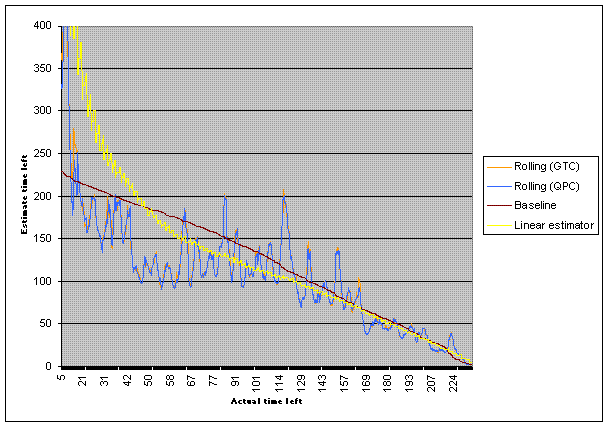
First, the download took almost four times as long. More importantly, the rolling methods completely fall apart, in the heavy Monday AM internet traffic. Increasing the rolling window size doesn't help much. Even if I increase it to 100, it's still so sensitive that it's almost useless for prediction. And by comparison, the overall smoothness of results of the simple method more than makes up for any small innacuracies:
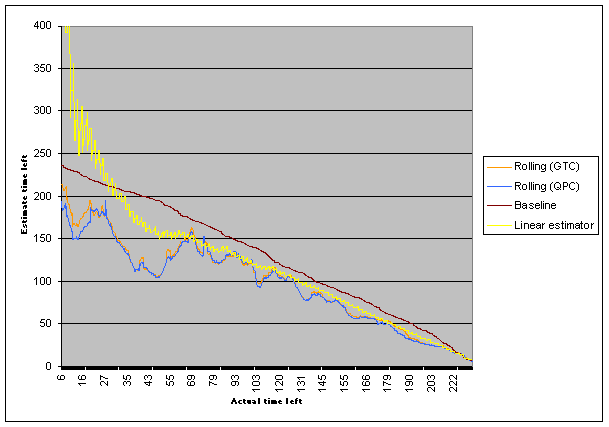
So, I guess that settles it.
One benefit i’d expect to see from the rolling method would be that delays early on in the download (such as those caused by other downloads chewing up available bandwidth) wouldn’t skew the estimate for the entire rest of the download.
yeah, that’s a good point.